Insights · Article · Data & AI · Apr 14, 2026
Grounding, retrieval guardrails, human sampling, and scorecards that keep assistive models helpful without inventing policy or leaking private data.
Support leaders want faster handle times and happier agents. Copilots can summarize tickets, suggest replies, and surface knowledge articles. They can also hallucinate refunds, misstate policies, and expose data if grounding is sloppy. Architecting a reliable support AI requires moving beyond basic retrieval generation and implementing hard deterministic guardrails that prevent rogue outputs from ever reaching the customer interface.
Quality assurance begins with corpus hygiene. Versioned articles, clear effective dates, and retired content removed from indexes reduce confident wrong answers. Garbage retrieval produces garbage suggestions. Vector databases must aggressively prune stale embeddings otherwise the model will resurrect policies that were deprecated months ago. Implement a strict pipeline that synchronizes your knowledge management system with your vector store using event driven webhooks.
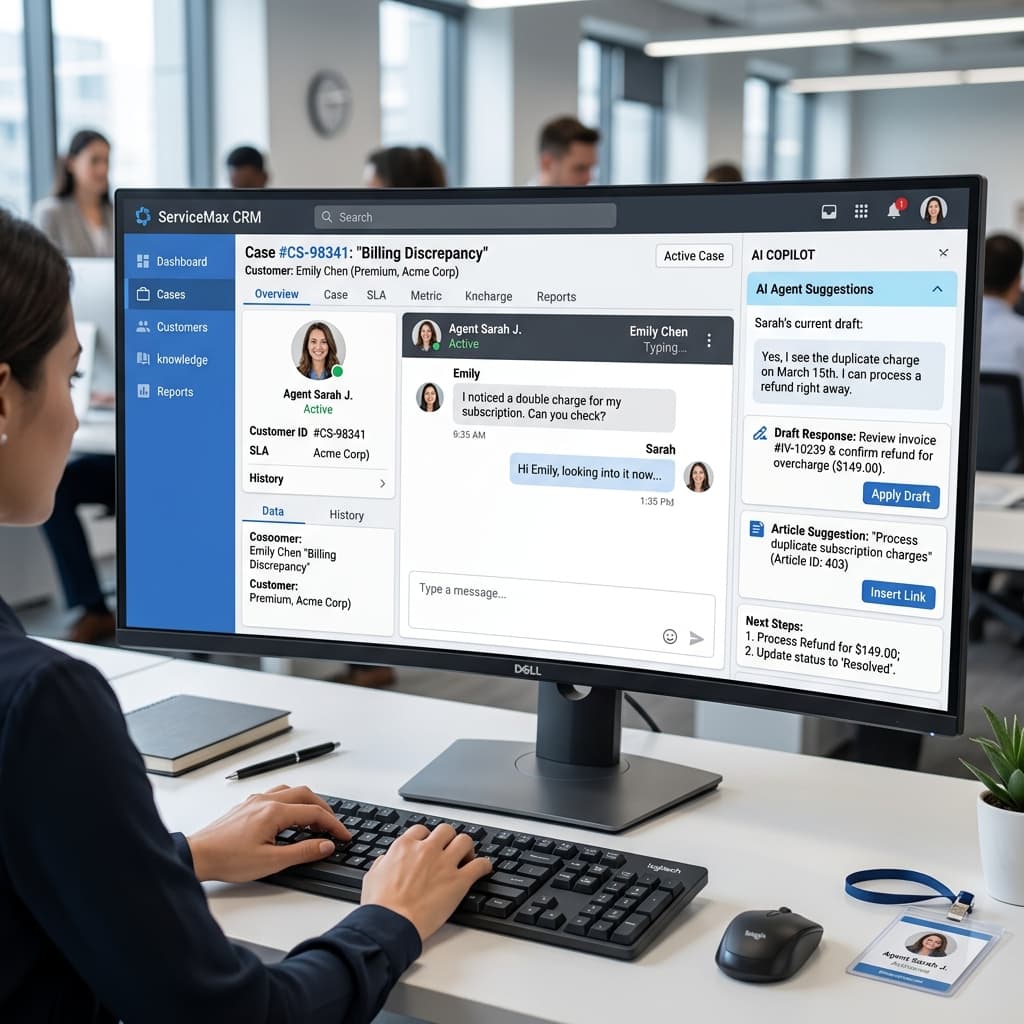
Retrieval guardrails include tenant isolation, role based scopes, and redaction of sensitive fields before model prompts. Test for cross customer leakage with automated adversarial queries. Personally identifiable information must be scrubbed using deterministic regular expressions before the context window is constructed. If you rely purely on the language model to redact data it will eventually leak credit card numbers or social security details in a summarized reply.
Human sampling should be statistical instead of anecdotal. Review stratified samples by channel, language, and issue type. Track disagreement rates between copilot and agent edits. Establishing a baseline acceptance rate allows engineering teams to measure the actual utility of the tool. If agents are deleting ninety percent of the AI generated text then the prompt engineering or the retrieval strategy is fundamentally flawed.

Feedback loops must be low friction. Agents should flag bad suggestions in one click with optional notes. Product teams should close the loop visibly or trust collapses. Implement a shadow evaluation pipeline where a secondary large language model acts as an automated judge reviewing the interactions against a predefined scorecard.
Latency targets matter immensely in high volume contact centers. If copilots slow the native CRM interface agents will actively find ways to disable them. Performance engineering belongs in the success criteria alongside accuracy. Streaming responses token by token can improve perceived latency but the backend retrieval phase must execute in under two hundred milliseconds.
Regulatory contexts may require strict retention of prompts and outputs with rigid access control. Work with legal counsel on data minimization and purpose limitation before enabling broad logging. Storing complete conversational transcripts in plain text within your observability cluster will likely violate compliance frameworks.
Executive dashboards can show containment rate, first contact resolution impact, and customer satisfaction deltas by specific cohort. Tie metrics directly to business outcomes instead of only tracking model perplexity. A highly accurate model that fails to reduce handle time offers zero return on investment.
Roadmap responsibly toward automation. Start with draft suggestions then move to pre approved macros and only later consider autonomous generative replies for very narrow intents with hard monetary ceilings safely in place.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.


